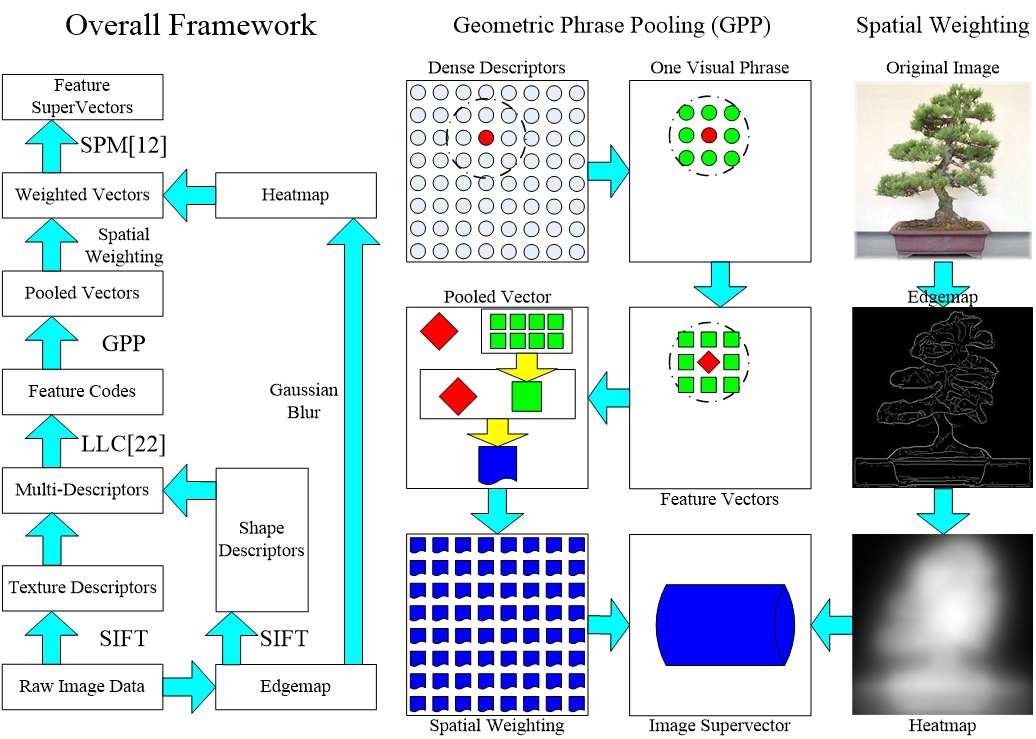
Introduction
EdgeGPP is an improved framework for image classification, built upon the traditional Bag-of-Features (BoF) framework [Lazebnik, CVPR06].
It consists of three individual modules appended to the BoF model:
- Extracting heterogeneous SIFT [Lowe, IJCV04] descriptors from both original and edge images to capture both texture and shape features.
- Exploiting Geometric Phrase Pooling (GPP), a mid-level local pooling algorithm to enhance the visual phrase representation.
- Blurring edgemap (intensity map in boundary detection [Canny, PAMI86]) for calculating spatial weights on the visual phrases.