Introduction
The CarLogo-51 dataset is a image corpus for large-scale near-duplicate image search.
It is collected from the Internet, composed of 51 categories of images containing famous car logos (see the figure),
and could be combined with any sets of distractor images in the Web image search tasks.
It is also a simulation of the Web environment, that every concept contains many instances.
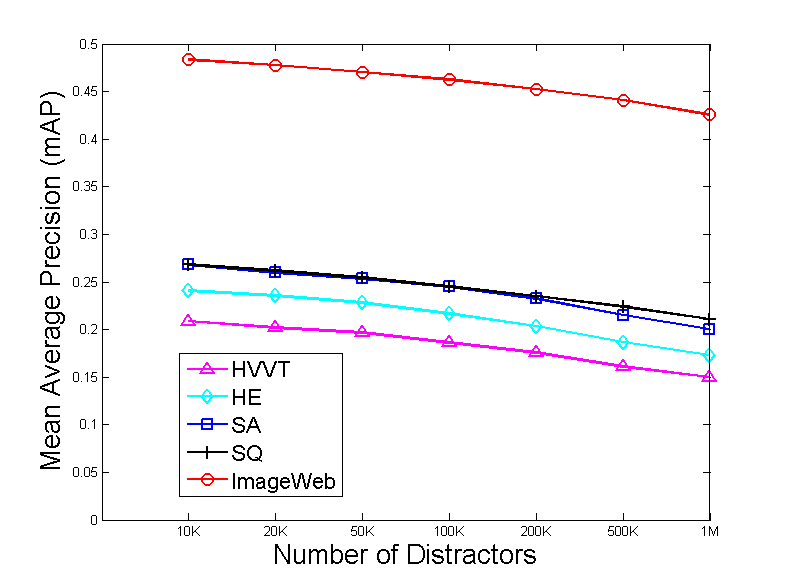
Therefore, we could adopt affinity propagation methods, such as ImageWeb, to improve the image search quality signi
cantly.